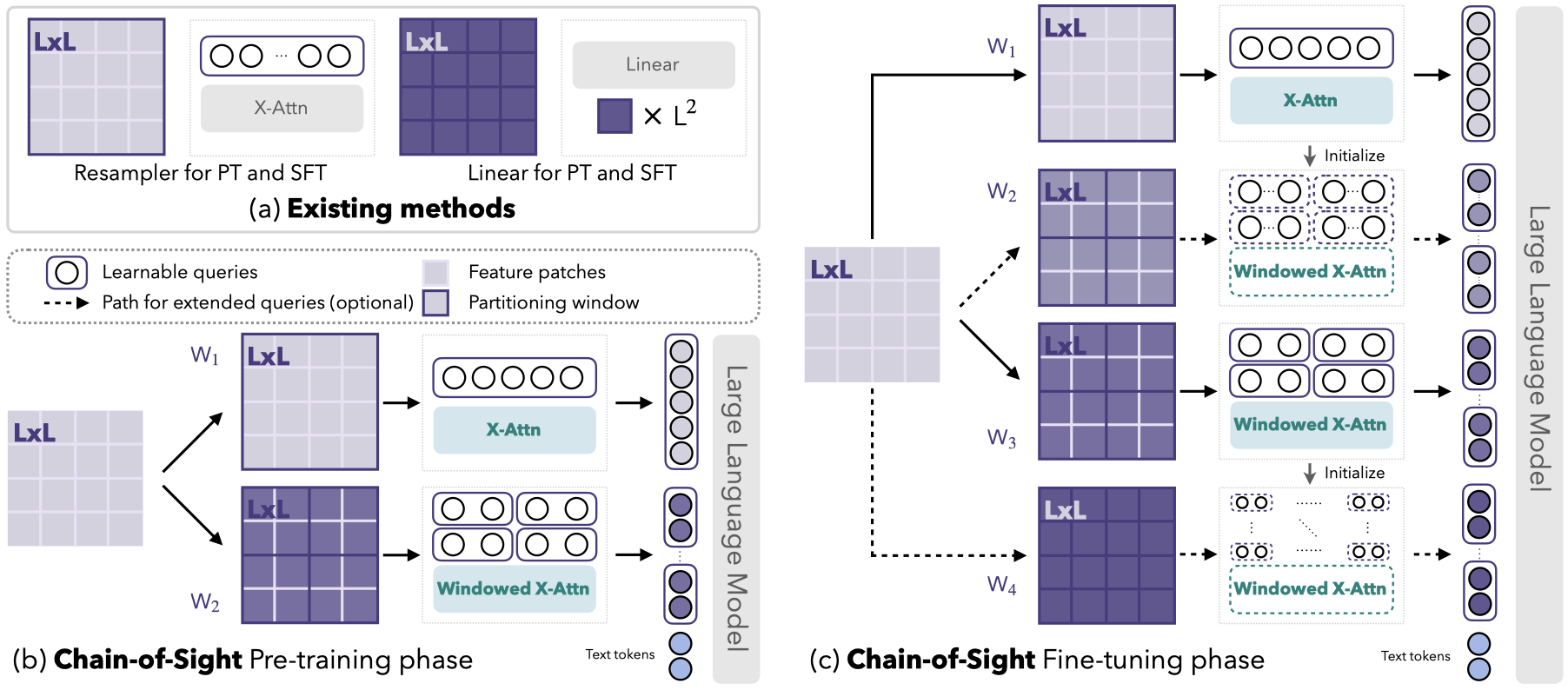
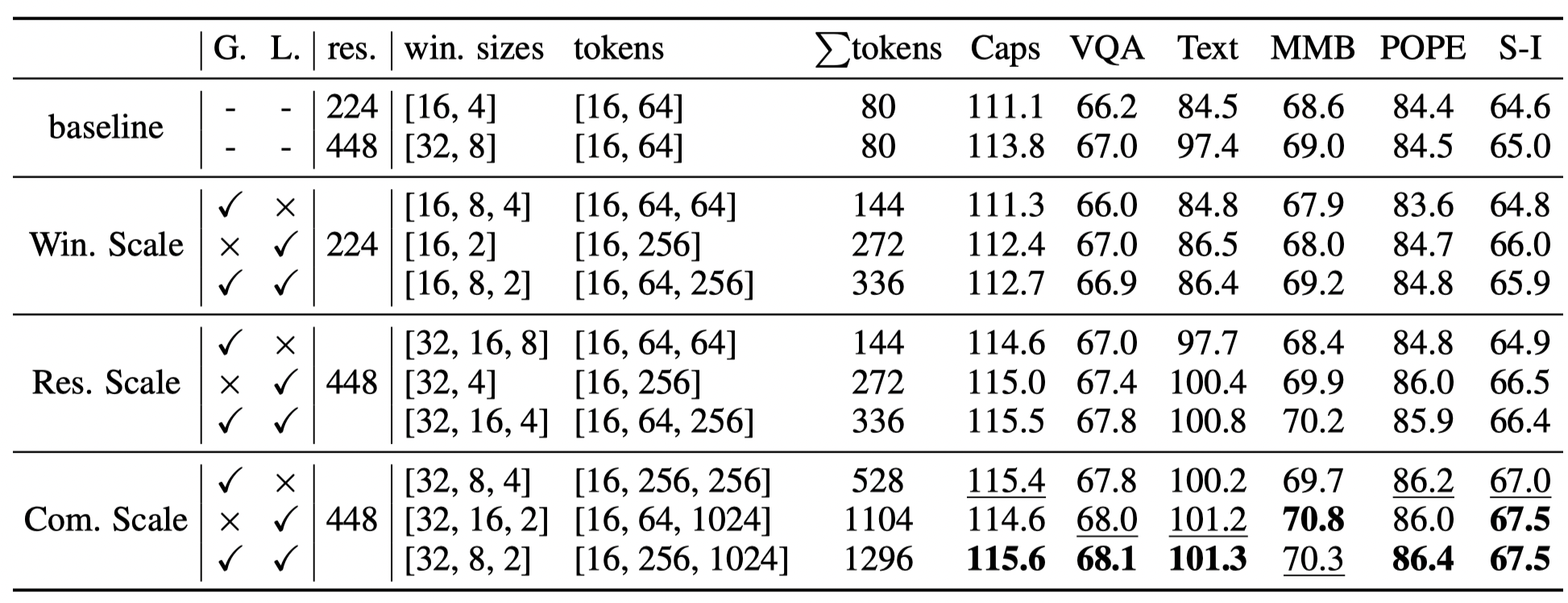
Our Chain-of-Sight integrates the idea of multi-scale hierachy to MLLMs, where visual contents are represented with a collection of visual tokens across various scales.
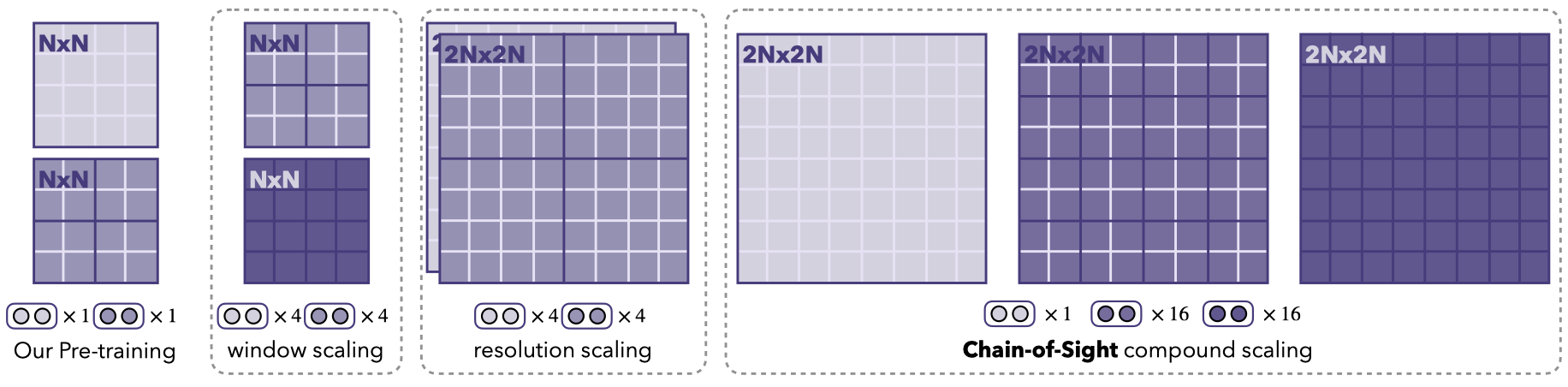
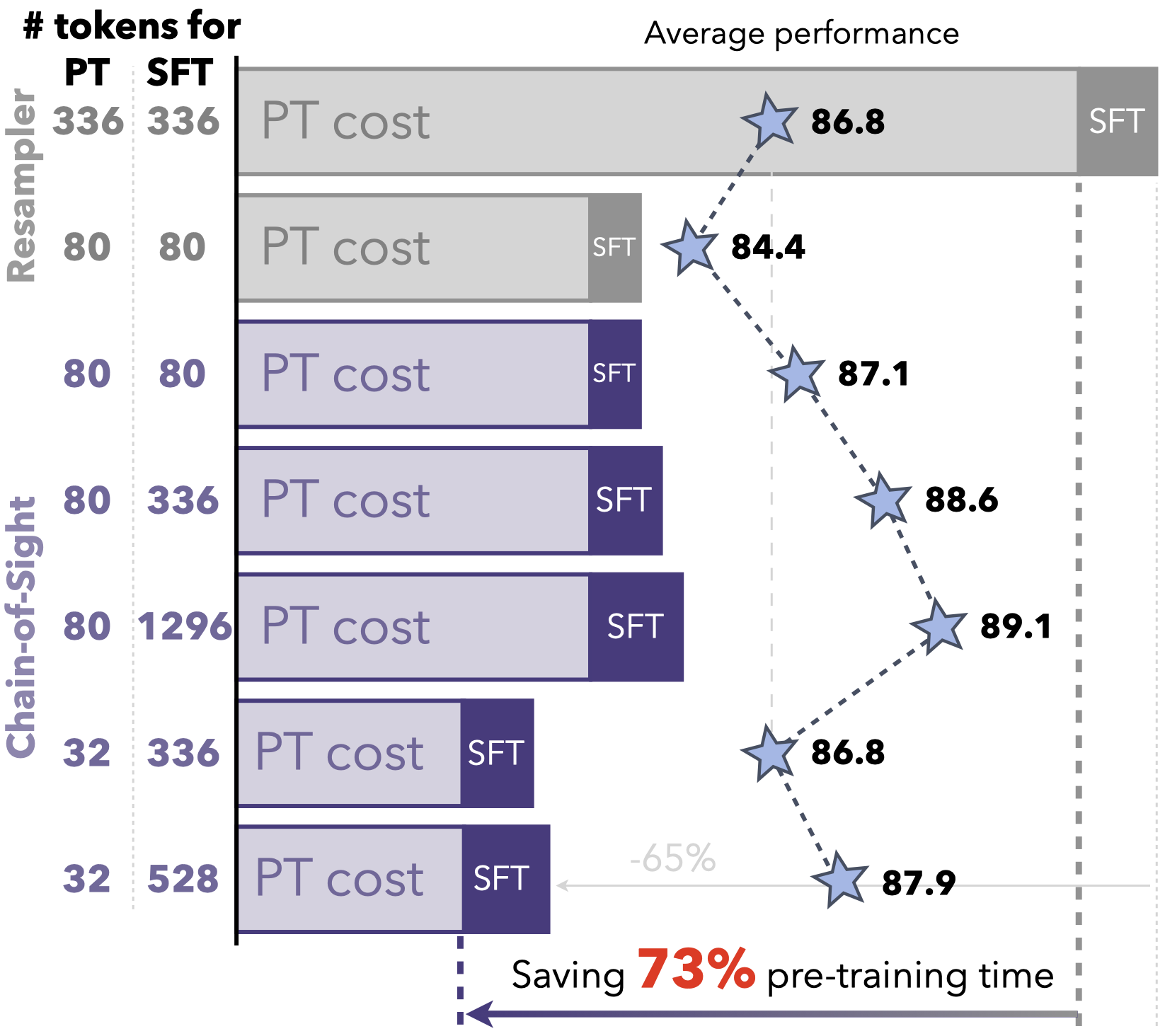
Thanks to Chain-of-Sight, we can achieve a 16-fold increase in the number of tokens after the pre-training phase.
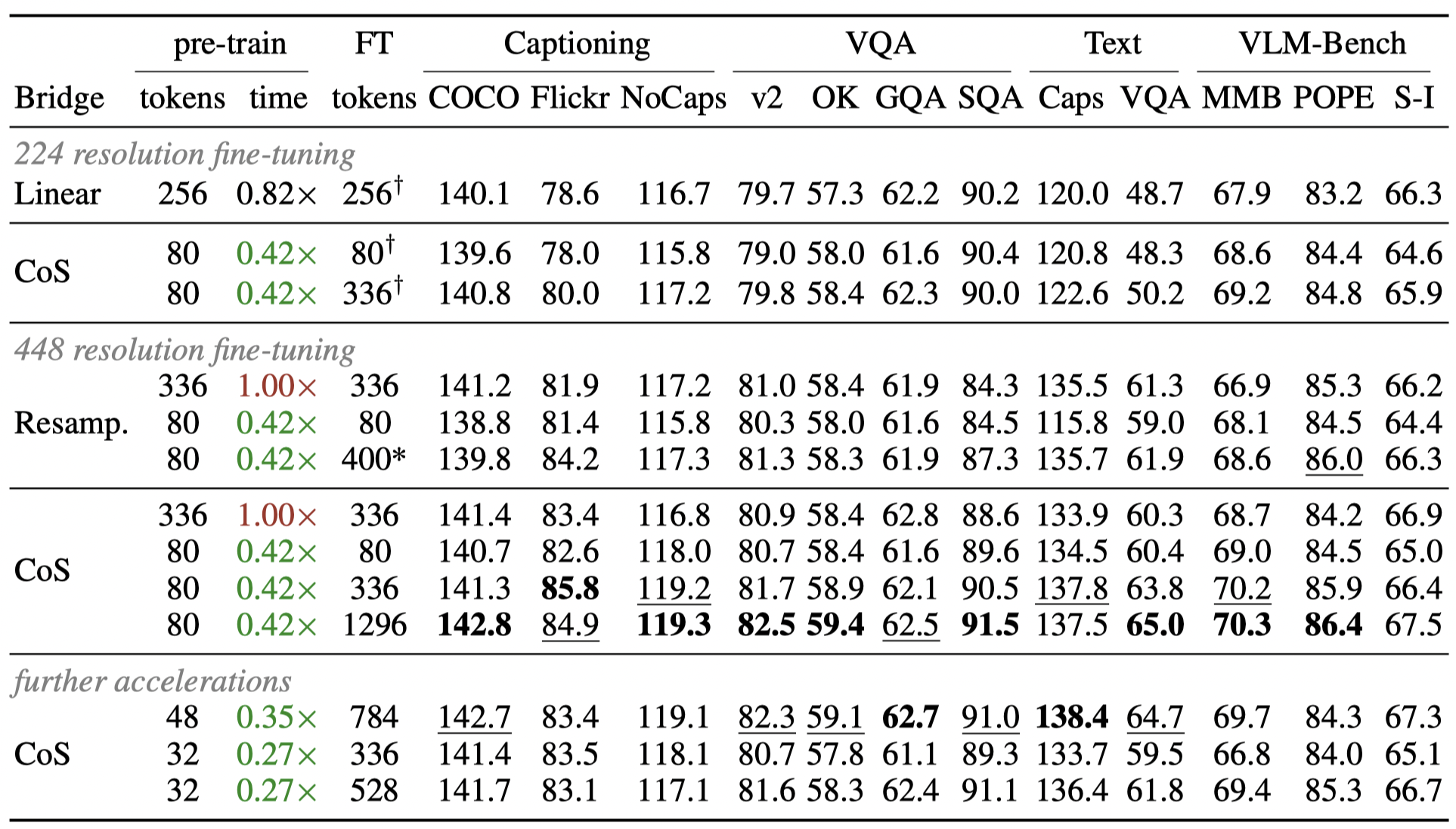
This scalability allows us to start with a substantially smaller number of visual tokens in pre-training, cutting down the wall-clock pre-training time by up to 73% without compromising performance.
Thus, Chain-of-Sight offers a powerful blend of training efficiency and enhanced visual detail, readying models for advanced tasks with both speed and precision.

Concept overview.
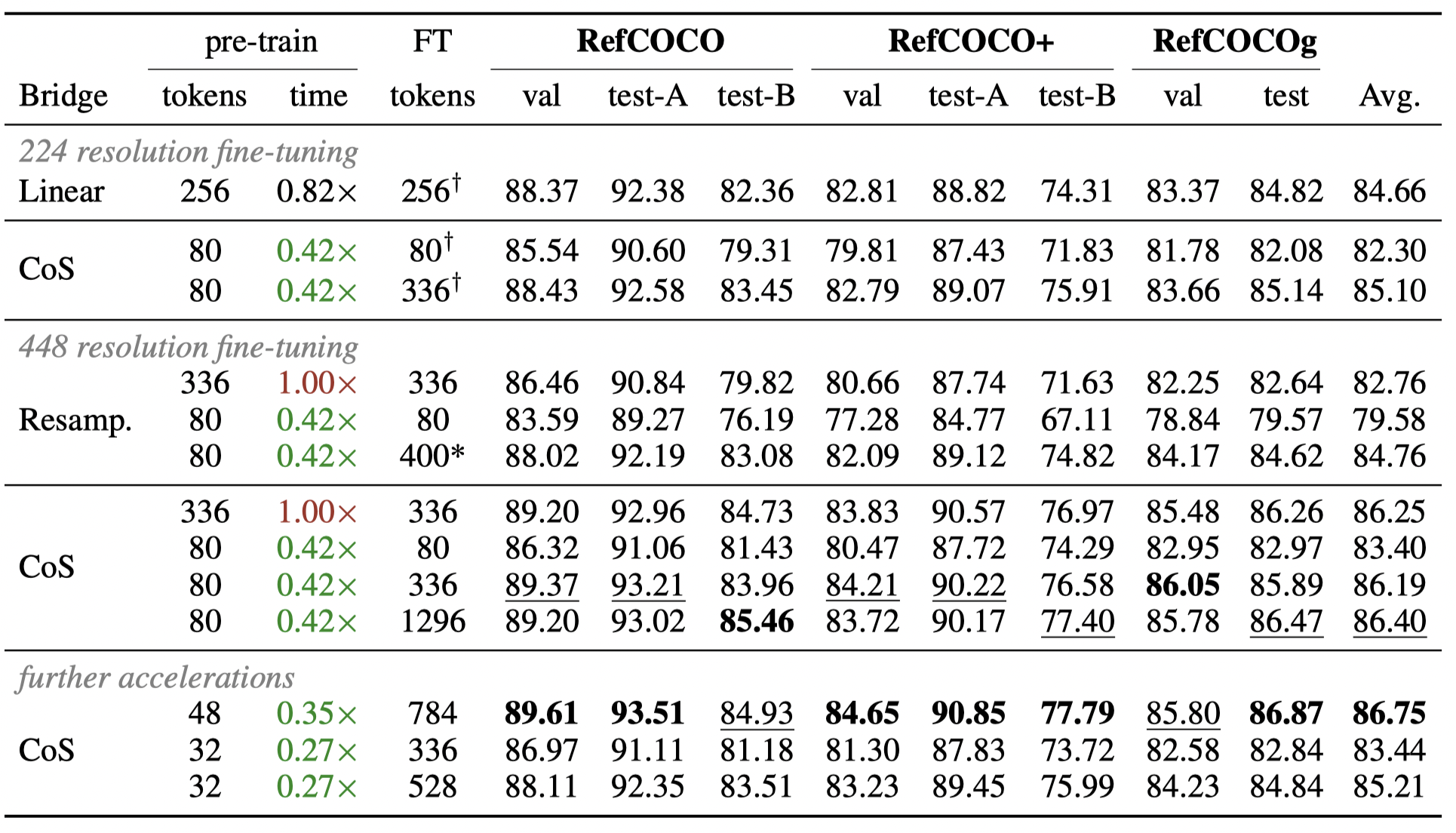
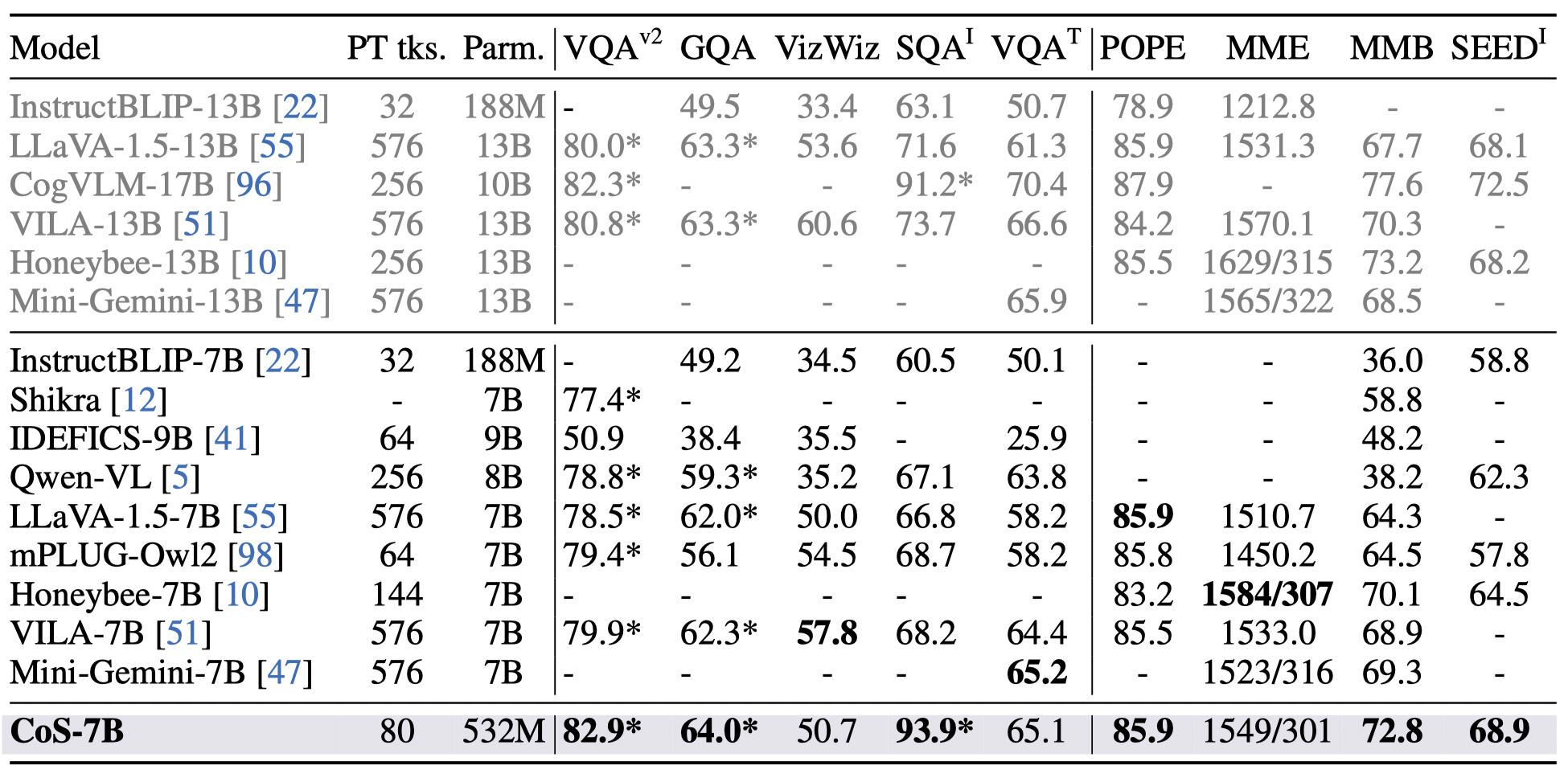
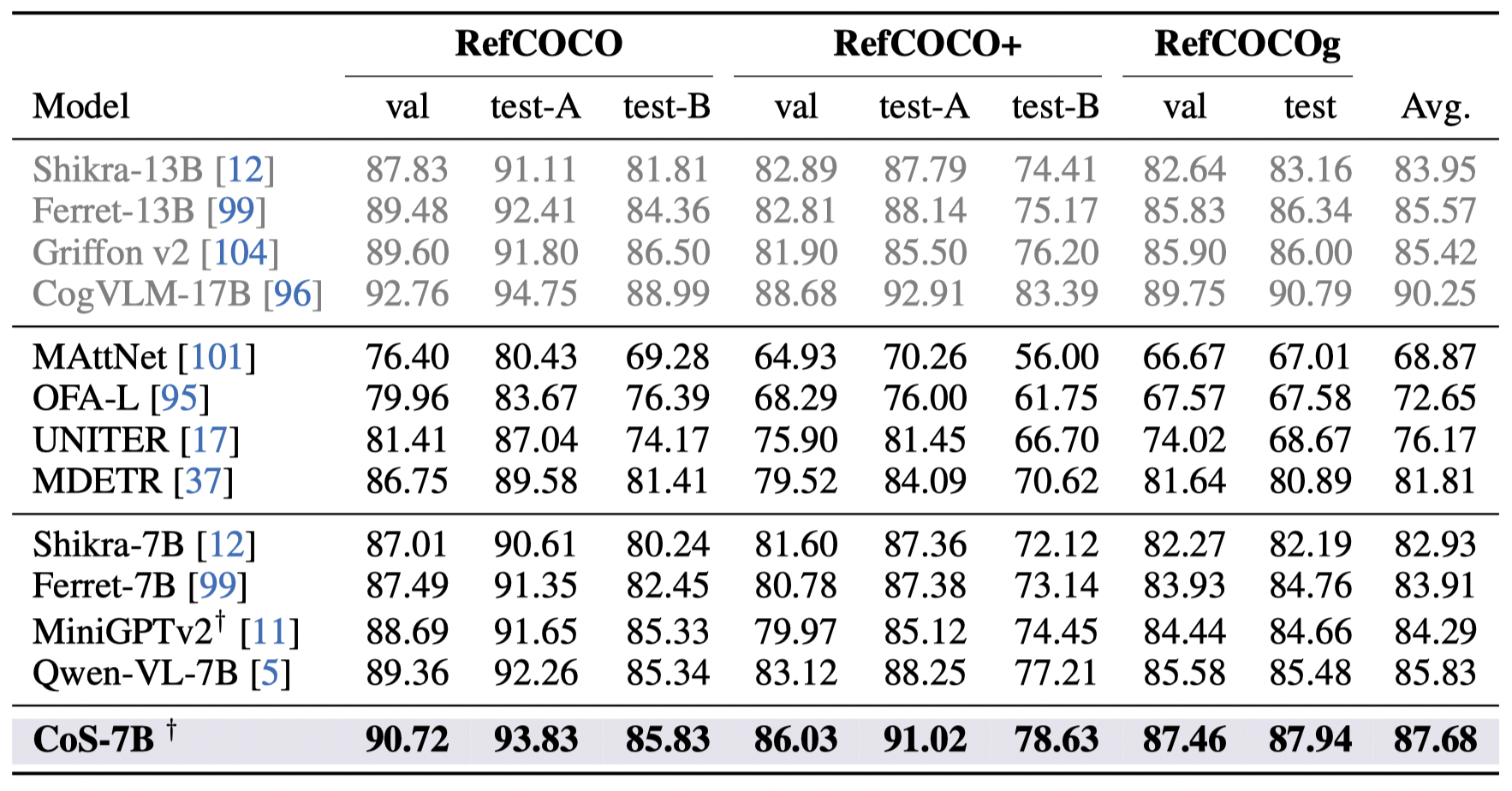
Performance overview.